PostgreSQL -How to Identify Duplicate Rows in PostgreSQL database
To find duplicate values in a PostgreSQL table, you can use the GROUP BY clause along with the HAVING clause. Here is the syntax:
SELECT column_name, COUNT(column_name) AS count FROM your_table GROUP BY column_name HAVING COUNT(column_name) > 1;where your_table is the actual name of your table and column_name is the column for which you want to find duplicates.
This query groups the rows by the specified column (column_name) and counts the number of occurrences for each group. The HAVING clause filters out groups where the count is not greater than 1, leaving only the groups with duplicate values.
Let’s look at an example. Below is the products table which has some of the products appearing more that once.

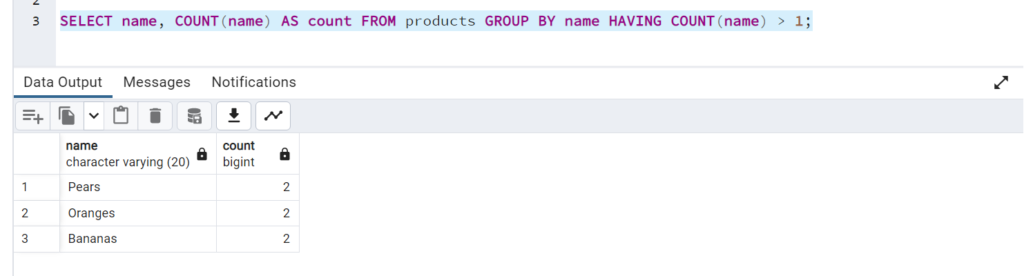
Below query is used to identify the names appearing more than once in the products table:
SELECT name, COUNT(name) AS count FROM products GROUP BY name HAVING COUNT(name) > 1;
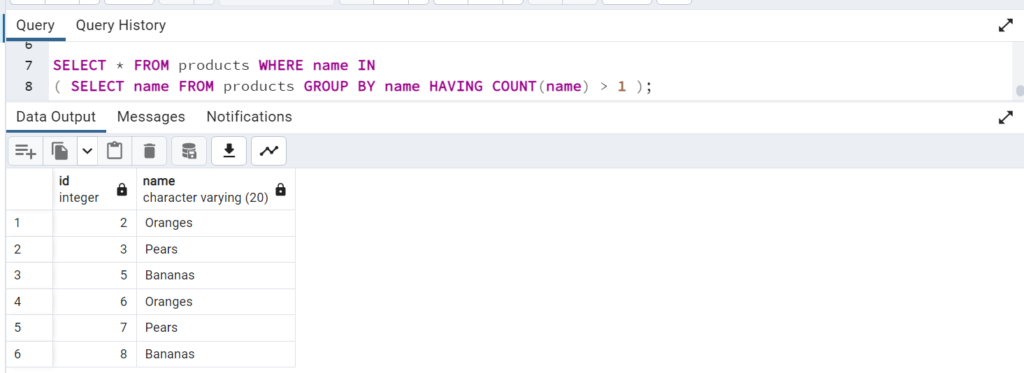
If you want to see the actual duplicate rows, you can modify the query to retrieve them as below:
SELECT * FROM products WHERE name IN ( SELECT name FROM products GROUP BY name HAVING COUNT(name) > 1 );