PostgreSQL – How to Delete Duplicate Rows in PostgreSQL Database
To delete duplicate rows in PostgreSQL using a self-join, you can use the DELETE statement along with a self-join condition. Here’s the syntax:
DELETE FROM your_table a USING your_table b WHERE a.column_name = b.column_name AND a.ctid < b.ctid;where your_table is the actual name of your table, and column_name is the column that you want to consider for identifying duplicates.
In this query:
aandbare aliases for the same table (your_table).- The condition
a.column_name = b.column_nameensures that the rows being compared have the same value in the specified column. - The condition
a.ctid < b.ctidensures that only the row with the lowerctid(physical location in the table) is kept, effectively deleting duplicates. If your table has a unique column, you can use the table’s unique id instead of ctid.
Let’s look at the below example. Here we have a products table with a few duplicate rows.(i.e) names are appearing more than once.
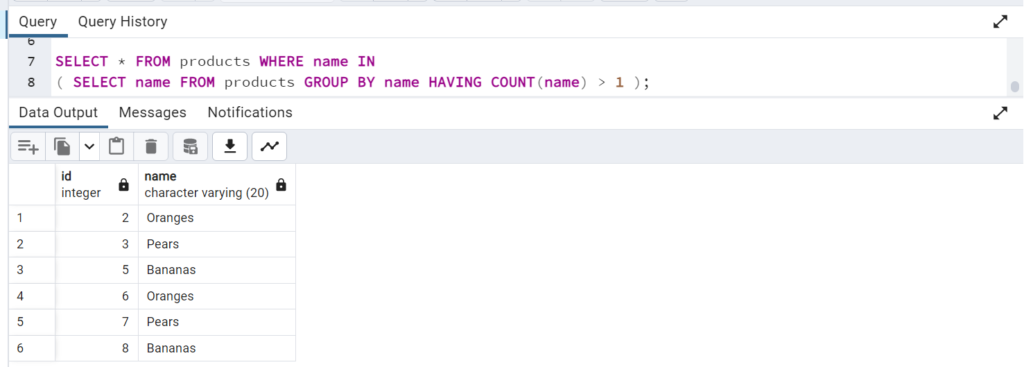
To keep the product name with the lower id and delete the duplicate rows , we use the below query:

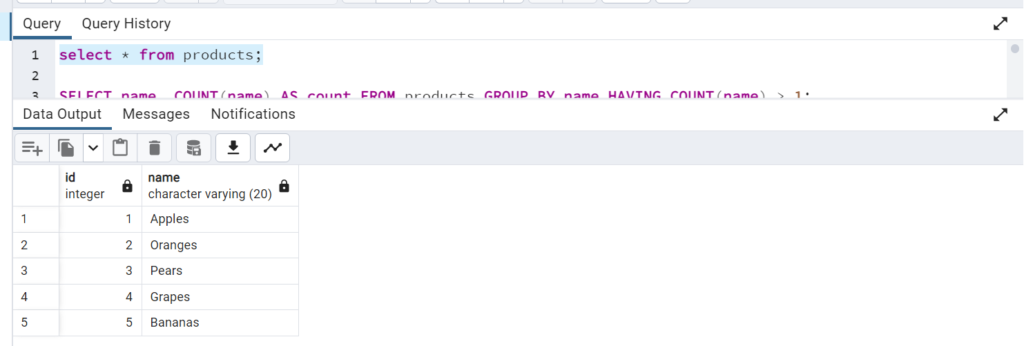
As you can see from above image, product id’s 6,7,8 have been deleted and 3,4,5 have been retained.